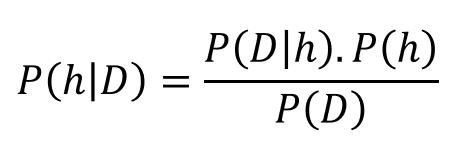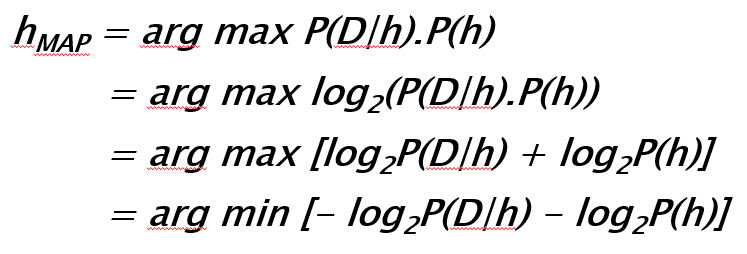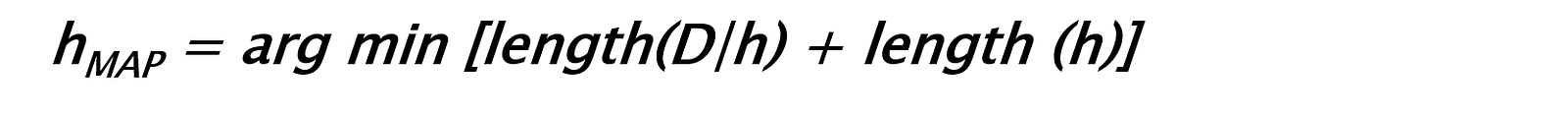Transcript
(Editor's note: transcripts don't do talks justice. This transcript is useful for searching and reference, but we recommend watching the video rather than reading the transcript alone! For a reader of typical speed, reading this will take 15% less time than watching the video, but you'll miss out on body language and the speaker's slides!)
[APPLAUSE] Hi. So I'm a legacy code mender. [LAUGHS] And by that, I mean I'm a person who finds bugs too boring to write, and so has dedicated my life to not only not really writing very many of them myself, but changing code so that other people don't write them, either. So I want to talk about that a little bit. There's a table. I can go in front of the table, because I don't need this for a minute.
So I'm going to tell a story of a couple of different companies. So one is Hunter Technologies. It's an interesting company down in the Bay Area. They've got a bunch of teams. This is where mob programming happened to be invented.
But I was talking with them about five, six years ago as they were starting to work in mobs. And they were telling about how they'd had this dramatic change in defect rate in the software. And what is that? And so they started talking about bugs, not in terms of bugs that were found, or found by QA, or found on the factory floor. They do factory floor automation. But it was the number that [? aren't ?] written at all.
And so I asked how many they'd had. And they said, well, this year there was one. And then I asked next year. And they said, well, it's only halfway through the year yet. So still zero. Over the course of five years, they had three. Now, technically, that's not bug zero. But I'm willing to give them credit. [LAUGHS] So that's one company, and one end of the spectrum.
And then there are many, many, many, other companies. And I've worked on a lot of code bases, everything from small four or five million lines of code to some of the larger 250 million lines of code sorts of code bases, anywhere from a dozen developers to 4,000 or 5,000 developers plus managers, and everybody else who's in the department, right? And their defect rates are not quite the same.
And I don't know about you, but I find the life experience of living in teams of these two kinds to be qualitatively different. And when my life is about finding bugs, triaging bugs, explaining why this bug is some other team's fault, and therefore I don't have to do anything about it, management decisions are about reporting bugs, there's no excitement there. There's no delivery of value to the customer. It's not fun.
So when I do work with software, I want to bring the fun back, and the fun comes from really working on the real stuff. And bugs get in the way. So I find bugs too boring to write. And that has caused me to really look at why do we write bugs, because I'm a developer. I have written bugs. I have never actually intended to write a bug. Has anyone in this room intended to write a bug? Wow, brave soul. [LAUGHS] We've got a few brave souls there.
So when you did that, were you actively testing your testers? Yes, OK. [LAUGHS] That is a good reason to write a bug, yeah. But that's about it, right? And yet, every bug is hand crafted, artisanal, made with care, one-off produced by some of the more brilliant and imaginative minds that we have out there.
So why do we make all those mistakes? Looking at it, I found there are a couple of reasons, and not many. But we've got some guides who can help us find these reasons. We will be in code in a little while. And I want two faces burned into your memory so that you can call out when those happen. So one is Inigo Montoya.
So the number one reason that developers write bugs is they're looking at some section of code they need to modify in order to change the behavior of the system, and this code does not do what they think it means. [LAUGHS] Yeah. When code is locally illegible, it's basically impossible to modify it without introducing a bug. As soon as my understanding of the code differs from the original artist's understanding, differs from the customer's understanding, differs from the computer's understanding, then it's just a matter of time.
So the first thing that we need to do to eliminate bugs is to make code legible. And actually, taking this to an extreme, I was looking at some research that was done in the early '80s on sources of bugs. It was actually intended to be an argument for why C was a much more effective language to program in than the things prior to it.
And the argument they tried to make was that it lets people work at a higher level, and you should see fewer bugs. And so in the process of doing that, they had to look at all these bugs, and see what correlated with it, and so on. And lines of code was highly correlated with bugs. And so they said C is better, because it was fewer lines of code than almost anything except COBOL at the time to do similar sorts of jobs.
But they found there was an even stronger correlation. The number one predictor of a bug in those programs is something that we have eliminated now. And that was inconsistent white space. You are more likely to cause a bug by changing the characters that are not noticed by your compiler than by changing the ones that are, because as soon as you have a mixture of tabs and spaces in the same file, or the wrong number of tabs on a line, then humans read that code very differently from how the machines read it, and bug.
So this problem went away significantly as soon as we all switched to using IDEs that auto format on every edit and save, right? Tools. By the way, one of the great ways that you can make a choice to live a bug-ridden life is to use crappy tools. [LAUGHS] Your choice of tools is a choice of how many bugs you want to write, and how many bugs you want to debug over your career. And even really simple ones turn out to make a big difference.
Second source of bugs. [INAUDIBLE]. OK, so assume that we've got code that I can tell what the heck it's doing locally. And there's still another really common cause of bug. I read this code, it makes total sense. I understand it. I make a change. It's just that my understanding of this turns out to be legitimate in the one context that I was reading it in. But it's got unexpected dependencies or interactions with foreign parts of the system.
And so it turns out it can be accessed in very different contexts, and it has very different purposes, and uses, and effects. And you see spooky action at a distance. I make a change here, and something over there breaks. Why? I don't know. So this occurs any time that we have behavior that is not locally determinable, nondeterministic. So you swallow a little more than you expect you swallowed.
So those are the two most common sources of bugs out there, as far as I've been able to see and understand from poking around a lot, and even reading some research. The next most common one is communications problems. The problem that the developer thinks their solving is not the problem the customer thinks they're solving. And that's also worth talking about, but not in this talk, because I want to code, and that one's not code.
So the last thing is when I talk about bugs, people nod along here for a little while, and they said, Arlo, but there's one more. And that is, my architecture is crap. This is a special case of that second bug. Yeah, I would like my code to not have spooky action at a distance. But remember those 10 million lines of code? They're all in one monorepo.
They are all compiled in one release. My build does take 2 and 1/2 hours to put everything together, and to run all our tests. I do have to test everything from the outside. We try and do unit tests, but you got to understand the size of a unit, right? [LAUGHS]
Yeah, so architectural flaws. So what we need is to do something that not only solves these couple of problems, but solves it in a way that can allow us to address fundamental architectural flaws throughout the system. And so these can be things like one project that I was working on, the project when we started, had a million and a half lines of ColdFusion, which was an interesting technological choice, given that no one on the team knew ColdFusion. And it was written like no one really knew ColdFusion. There was a lot of SQL in it.
And so we decided to make a shift. And we were going to move this to ASP.NET NVC, and C#, and all the goodness. And a million and half lines to do that conversion. Well, we were doing medical claims processing. And it turns out people don't stop getting sick or hurt just because you want to change technologies.
So it's really a good idea to keep being able to process claims. And furthermore, the government doesn't stop changing regulations, nor do doctors and patients stop finding new ways to commit fraud, just because you want to change technology. So we needed to be continually releasing the whole time. So we did our shift gradually from the one language to the other from a procedural style to NVC style, releasing four or five times every day the whole time through, and adding new features along the way.
And here's how. So this code base is what you get if you're a loud mouth on the internet. So I was talking with people on the internet. And I have a perhaps well-known distaste for mocks. I think mocks are evil. With good evidence, I think they're evil.
And so after one of many loud conversations about this, someone said, all right, but they're a necessary evil. I'll give you some code. Try and test this without using any mocks, or fakes, or anything. So that's what this program is. And it is not intended to be perhaps in the optimal state for testing. So it's one simple 80 line function. That's the whole program. It works, trust me. Oh, by the way, there are three bugs in this program. Did anyone spot them?
[LAUGHTER]
Yeah. [LAUGHS] I didn't either, for a while. So I went ahead and I did this on my own once about two months ago. And I haven't looked at it since. So I figured I'd do it live in front of you guys. And let's see where it goes. So our objective is we have this piece of code, which presumably, I'm going to make some future change in.
And we'll just go ahead and make it easy. We'll say that the customers have identified-- there's some funny thing that happens with critics being overly trusted with some particular sets movie reviews. Now, if you don't understand what the hell I just said, that's fine, because neither did I. I know nothing about this domain as we start.
So we want to find and fix that bug. What do we do? [LAUGHS] Run it? OK. Actually, I don't really know how, because you see, as I start to run it, at least when I first got it, this program linked against a version of SQL Server that was old enough that I couldn't get an installer for it. [LAUGHS] So find the bug. [LAUGHS] By the way, you can't run the program.
Anyone have another idea? It does compile, so it's not bad.
[INAUDIBLE]
Yeah, why don't we do some of that? So I already did the first couple of commits here. I put it into a solution, and I auto formatted the document. So at least white space is consistent, and those sorts of things. But yeah, why don't we get it to be readable?
So the first thing that I notice is functions, especially legacy functions, tend to have a pretty standard structure. First, you get the wrong arguments. You have a useless name. In this case, Main. That's real hopeful. That conveys a lot of information. And then you get the useless arguments. And then you have a chunk of code, which transforms from the wrong arguments to the data you wish you had.
Then once you have the data that you wish you had, you do some amount of work. I don't know what the work is in this case. And then usually, at the end of doing that work, you prepare some information that you give back to the caller. In this case, it doesn't look like we do much of that. It looks like all the work is done by side effects. So that'll make it even more fun to test.
So let's just go ahead and get started. The interesting part of any function that has that structure is generally in the middle. So usually, what I'll do is I'll go to the bottom of the function, like I just did, and then I'll scroll up to find the first block, first large block. And that's this one. And it's nice, because someone even tagged it. So let's just start making it readable. OK. Can anyone tell what Main does now?
[LAUGHTER]
Maybe I don't know what it does, but I have a good guess. All right. So what am I doing here? Any thoughts?
You're refactoring.
I'm definitely refactoring, yeah. [LAUGHS]
Breaking it into smaller units.
Yeah, I'm breaking it into smaller units. But there's a really important thing that I'm doing. It's not just that smaller units are easy to understand.
Giving concepts to names.
[INTERPOSING VOICES]
Bingo. Giving names to concepts, yeah. And so the console read line was a particular one where I guessed what that concept was. And I'm giving it a name. Now, you could see also from this that I might not be completely confident in my belief that that's the right concept here.
So what I'm trying to do here is I'm working through creating names and creating concepts along with them, but it's an iterative process. So I've just done a couple of things. That's way more code than I ever want to have not in source control. So I'm about to commit to source control. What's the probability that I broke something?
Low.
Low, OK. Is it low enough? Do I understand this code?
No.
No. [LAUGHS] Do any of you understand this code?
[LAUGHS] No, OK. So pairing and mobbing, none of that's going to help me here, right? [LAUGHS] So what I'm trying to do here actually is read the code. So recall the whole point of this is to reduce the number of bugs that I write. So when I'm reading code in a normal traditional style, what's the probability that I introduce a bug?
Zero.
Zero, yeah. If I don't change anything, then it wasn't me that introduced the bug. Maybe an operation system went down or something, but clearly, it wasn't my code edit, right? So what I need to do is have the same probability. What I really want to do is develop a way of working that is uniformly better than my old traditional way of working.
So every type of work that I do has no more risk than it did before, no more cost than it did before, and I can drive the total cost and risk of software development down, and spend a lot more time doing things for my customers or playing foosball, and a lot less time fixing bugs. So is low good enough? No. It's not zero.
So that's an interesting question, because then the question is, so how do you get it to low enough? Did I run any tests? Nope? Am I going to run any tests?
[INAUDIBLE]
Yeah, actually, I do have NCrunch running. And it did auto run a test. Do you want to see what that test is? This is a fantastic test. It tests all the things by verifying nothing special. [LAUGHS] How much confidence do you have in the test suite here?
Zero.
Zero, yeah, approximately, yeah. So it does verify that NCrunch is working. That's good. [LAUGHS] Yeah, so I need to have confidence that I didn't break anything, that I'm basically zero probability of breaking things. And I don't have tests. That's OK, because actually, the level of proof that I need of 0 is higher than any test we could find.
So what I need is not only did I not introduce a bug. What happens if this system has been used for 25 years out in production by some companies that aren't me, and they've extended it, hooked into various APIs and called them, and they paid some attention to the API documentation, but mostly they just poked at it and saw what worked, and what the behavior was, m they wrote code that integrates against it. And they're now running a multi-billion dollar business off of that, and they lost the source code about 10 years ago. What happens if I accidentally fix a bug?
Yeah, I can't afford that, right? So I need bug for bug compatibility. I need to be able to guarantee 100% that not only did I not accidentally introduce a bug, I didn't accidentally fix a bug that I don't even know exists. All right, so if I'm going to prove that I didn't fix something that I don't know exists, is my test suite have any use? No. Everything in the test suite is something that I at least, at one point, knew existed.
So I need a higher standard of proof. And I actually do have the higher standard of proof right now. It just happened so fast that probably very few of us saw it. What do I have that's giving me enough evidence that I feel confident I'm actually 0% probability I changed behavior here?
Tools.
Tools, yes. ReSharper in particular, in this case. The refactoring tools, yeah. And if I don't have these tools-- by the way, part of my day job, I do a bunch of this work in C++, too. The tools in C++ are not quite up to the same standards of tools in Java or C#, but we need to have the same confidence.
So we've created there a bunch of recipes that lean on the compiler, because these tools and the compiler have something in common. They're using static analysis. They're analyzing the program to know for sure what changed, and what didn't. So what I need to do is create a way of working that leans on whatever static analysis or other proof systems I have available, and guarantees that each transform is perfectly safe.
Now, this is important for a number of reasons. One, because zero, it's a nice number. But another is if we look at the tree of the last time I did this, I worked for 11 hours, which is 244 commits. And I was going little slow, but not too bad. And I did get lost in the weeds. I didn't have a partner, so there was one period where for 45 minutes, there were no commits. And if I'd had a partner, eight minutes into that, he'd slap me around. [LAUGHS]
So if I'm doing 244 of these transforms, and I have a very small probability of error, the probability of error at the end is much higher. And the place where I found the bug was somewhere around here. It was somewhere in there. I've forgotten exactly. But it has 180 commits in, 160, 180, somewhere in there.
I need to know for sure that I didn't just introduce that bug, that that bug was actually there in the original. Otherwise, I'm not going to be able to have the right conversation with my customer to find out whether they're depending on it or not. So static analysis, tools, it's the thing.
So let's carry on for a little bit more. Let's look at these names. Process rating. Well, first, this one. Is that name better than what was there before? Yeah. Is it any worse than what was there before? No. Let's look at the other one. Process rating. Is that better than what was there before?
It's the same? So what do you mean by it's the same?
Because the other code said process rating, and it had that [INAUDIBLE].
Right, so the previous code had a comment saying process rating, and then had the block. Yep. So it's a little bit better in that at least the block is separate and I can see what data is flowing in and out of the block. And that's good. But the name is equivalent. Is it any worse?
Could be wrong.
Could be potentially wrong, yeah. So I've just taken something that was in a comment. How much do we trust comments?
[LAUGHS]
Right. And I've put the same text in a method name. How much do we trust method names? More than we trust comments. So if I want to be able to trust method names in this system, I can't take information that was untrustworthy and now pretend it was trustworthy. In that way, I have made it worse. I've potentially fooled people that follow.
[LAUGHTER]
Now is it any worse? So this is a mechanistic sequence that I call naming as a process. And it goes through several steps. And the first step is usually take something missing, it doesn't have a name at all, and name it Nonsense. I find a method. It's a few thousand lines long. I don't want to read it, but I know it's one block, and it's not related to the code that I want to do.
I'll name it Applesauce, because unless I'm working at treetop, I know for a fact Applesauce has nothing to do with my domain, and everyone in the company will not mistake that-- [LAUGHS] --for anything sensible right it's obvious nonsense. At least I've taken it from not so obvious nonsense to obvious nonsense. It's better.
Then the next step is honest. And the problem with process raiding was it was neither obvious nonsense, nor was it honest. Process rating, I think, is honest. Make sure that I'm on the right one. Yes, I'm on the right one. What are you? Go away. OK.
All right, so now I can continue along in this line. And in fact, what I did the last time I worked on this, I did continue along in this line for a while. And eventually, I could figure out what process rating really is. Oh, and by the way, this comment is not providing much value anymore. I could delete that comment.
And I can figure out what it does, and continue working on in that. And that's a good thing, and it's good direction. But there's another direction that's worth exploring here. And that is we talked about, well, what about when my real problem is the full system design?
So this application is designed as one procedure that runs top to bottom, and executes a sequence of arbitrary link statements against the database with most data held between statements just in whatever's in the database, and a few things in local variables. That might not be an optimal design for the ability to reason over it, or the ability to test it.
So I want to do some refactorings to start getting some better stuff there. So one of the first things that I notice as I look at this is, remember the part where I said we get input in an annoying format, and then we figure out the data that we wish we had? So it looks like the data that we wish we had are a movie ID, a critic ID, and stars. I don't know what stars is, presumably the rating in number of stars.
So we're passing around these three values. Now, any time that I see us passing around multiple values, all of which are primitives or low level things, that's three ints. Ints don't have anything to do with my domain. So therefore, not much value here. That tells me that I need a domain concept. Let's extract class from parameters. Anyone know what this is?
Rating.
Rating. Sure, let's call it a rating.
[LAUGHTER]
OK. And I now have this rating, I think, class. Well, that's nifty. I certainly don't want that in the same file here. What? You're just not going to auto fix it for me? OK. OK. I don't know what you are, but you are going away. Die, die, thank you.
So I've just created this rating class. Now, that's cool. What did it-- It was complaining that it couldn't write to some of these things. So hey, look, ReSharper has a bug.
Have you tried their tools?
[LAUGHTER]
It's a really important question there, because the truth is that our tools are imperfect, all right? But they have the advantage of being consistently imperfect.
[LAUGHS]
Myself, I am inconsistently imperfect. So I can learn what my tool does safely, and what it doesn't do safely. And for the things that it doesn't do safely, I can file a bug. And they'll actually fix that, whereas filing a bug on myself of, you should be a little better at making this mistake less often. Good luck fixing that. And it also wants to know our constructor. Sure, great. Initialize with garbage, and allow me to do things.
Ah, there's what actually happened. Didn't see that until we got here. So we screwed this up when we did our rename. So when we called it Rating, we introduced a collision on the class name Rating with something that was in the database. Turns out, that name was already used in our domain. So by going through the named rating, I collapsed two ideas on top of each other, and it gets all screwed up.
So fortunately, that's why we have this, because I just wasted an entire five minutes of work there. But I'm back to a known good state. So we can't call it rating. Instead, I'm going to call it Rating I Think, because that is a unique name.
Now, the first time that I went through this, I happened to call it Critique. And so I got lucky, and everything was good. Now, if I was paying attention to my tools, NCrunch actually was telling me the whole time that the damn code didn't compile.
OK. Cool. Now I've got class. OK, Stop Build. I'm surprised it succeeded, given that there's no internet in here. So NuGet's not going to work very well. OK, so now I see some other issues with this code. How many people like line 27?
None.
[LAUGHS] None. And none of us like line 27. OK, so let's make that a little better. It seems like it's the new rating, the one we're going to add. And now we've got this method down here, Process Rating I Think. As a static method that takes one of those, I sure wish that instead, it was-- really? OK. Presenter Mode has put things on top of other things. What do I want? I want to make instance method, which I'm not finding.
Second from the bottom.
Second from the bottom? Thank you. There we are.
[INAUDIBLE]
Thanks. OK. Poof. And now up there. So what's happening here is I'm discovering, as I go, little pieces of the domain. I still don't understand what the program's doing. I don't need to understand what the program's doing. I'm discovering what the program is doing, all right? An any design choice, which a prior programmer or me has made, is amenable to change, as long as I've got enough refactorings.
And so then there's the question of, are there enough refactorings? Turns out, if you look at all the ones that are available in Fowler's book, there seem to be, can go from pretty much any arbitrary design choice that someone has made to a new design in a sequence of, well, it might be hundreds or thousands of refactorings. But if each one's safe, I know I'm good.
So this gets us back to that. I can address architecture flaws. I just don't address architectural flaws at once. But when I'm working this way, how long is it before I can ship this code?
Now.
Now, yeah. When was the last point I could ship this code?
[INAUDIBLE]
10 minutes ago, because I made a mistake. [LAUGHS] Right? Yeah. So I can attack an extremely aggressive architectural flaw, the kind that take a year and a half to fix. And I can release every five or 10 minutes, the whole time that I'm doing it, which means when developers are writing bugs, they're writing bugs because the code is setting them up to write bugs.
And yet, I just said any flaw that's in there, including an architectural concern, we can now fix and chip away at without introducing bugs. That's what allows us to dramatically reduce the number of bugs that both I write, and that the future person writes. And the question is, can you afford it? We didn't understand this code. Do we understand the code a little better now? A little bit. I understand it a little bit better.
How much time do you think in normal dev spends in a typical day trying to read code to understand what it is, or navigate and scan around code to find what code they should read? Percentage of their work day. Any guesses?
90%.
90%, 80%, 50%. Yeah. So I've seen numbers do vary. There was an Eclipse study that they turned on their telemetry, and watched what people are doing. And they found the amount of times that people were just Alt tabbing between files, and scrolling around in them, and times when people had one piece of code on the screen for a long time, and then would click on things, and so on. [LAUGHS]
And they found that to the best of their knowledge, they saw that developers spent about 70% of their time reading or scanning code, and then about 15% of their time testing or debugging, depending on the developer. Take your pick. And then they spent about 10% of the time actually writing and editing code, and then other time for other things. So if we were going to optimize the developer, where's the place where we would make the biggest savings?
Readability.
Readability. It's in reading the code. So if I'm facing a 10,000 line method, and I try and read it, how long is it going to take before I understand that thing well enough that I can edit it?
Never.
Never. [LAUGHS] Yes. If I drop it to only 150 lines, a day, maybe a little less. What we're doing here is we just have one insight at a time, and we record it. And that takes the things from our mental field, and puts them in our visual field, and we get one idea at a time, and we build on that. This code, which you could not understand before, is getting pretty understandable. It's still got this block at the top. But after that, it's pretty straightforward.
So what we do here actually decreases the time it takes to read code. So we can pay off technical debt, architectural debt of the kind that is causing us to write bugs in a way that decreases the amount of time it takes us to write code, and without introducing bugs as a side effect. This is why discipline refactoring and really good tools are really really, really handy. [LAUGHS]
And the message that I want to get out to all the other people out there who would like to be legacy code menders and work in a system that has no bugs. You can do it. It's a matter of working in really tiny high-discipline steps, and composing those at read time so that by the time you go to write and edit any code, it's all easy to work with. Thank you very much.
[APPLAUSE]
 An 88-year-old message in a bottle was found under the roof of the cathedral vestibule in Goslar, Germany. (Julian Stratenschulte/Picture-alliance/DPA/AP)
An 88-year-old message in a bottle was found under the roof of the cathedral vestibule in Goslar, Germany. (Julian Stratenschulte/Picture-alliance/DPA/AP)